Broader Impacts of this Project
-
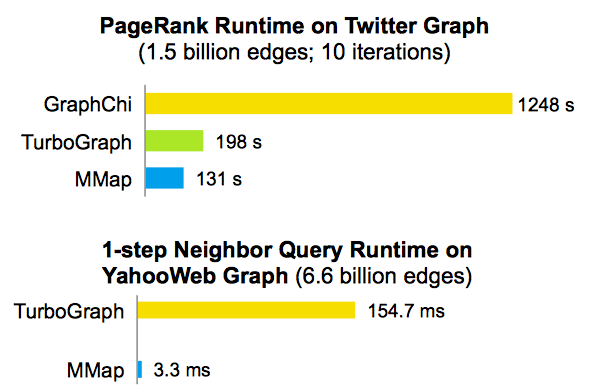
 Faster I/O Operations
Faster I/O Operations
-
 Less Overhead
Less Overhead
-
 Simpler Code
Simpler Code
Research Goals
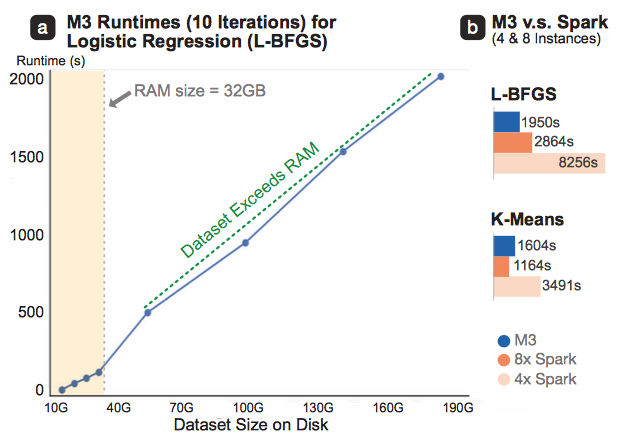
This project investigates a fundamental, radical way to scale up machine learning algorithms based on virtual memory, one that may be easier to code and maintain, but currently under-utilized in by both single-machine and multi-machine distributed approaches. This research aims to develop deep understanding of this radical idea, its benefits and limitations, and to what extent these results apply in various settings, with respect to datasets, memory sizes, page sizes (e.g., from the default 4KB to the jumbo 2MB pages that enable terabyes of virtual memory space), and architectures (e.g., testing on distributed shared memory file systems like Lustre that support paging and virtual memory over large computer clusters). The researchers will build on their preliminary work on graph algorithms that already demonstrates significant speed-up over state-of-the-art approaches; they will extend their approach to a wide range of machine learning and data mining algorithms. They will also develop mathematical models and systematic approaches to profile and predict algorithm performance and energy usage based on extensive evaluation across platforms, datasets, and languages.Significant speed-up over other single-machine approaches
Works for datasets as large as 200GB, at speed comparable to 8-node Spark
Publications
Most Relevant Papers
M-Flash Fast Billion-scale Graph Computation Using a Bimodal
Block Processing Model.
Hugo Gualdron, Robson Cordeiro, Jose Rodrigues, Duen Horng (Polo) Chau, Minsuk Kahng, U Kang. PKDD 2016. Sept 19–23, 2016. Riva del Garda, Italy.
M3: Scaling Up Machine Learning via Memory Mapping.
Dezhi (Andy) Fang, Duen Horng (Polo) Chau.
SIGMOD/PODS’16.
MMap: Fast Billion-Scale Graph Computation on a PC via Memory Mapping.
Zhiyuan Lin, Minsuk Kahng, Kaeser Md. Sabrin, Duen Horng Chau, Ho Lee, and U Kang.
Proceedings of IEEE BigData 2014 conference.
Oct 27-30, Washington DC, USA.
Towards Scalable Graph Computation on Mobile Devices.
Yiqi Chen, Zhiyuan Lin, Robert Pienta, Minsuk Kahng, Duen Horng (Polo) Chau.
IEEE BigData 2014 Workshop on Scalable Machine Learning: Theory and Applications.
Oct 27, 2014. Washington DC, USA.
Related Papers
VISAGE: Interactive Visual Graph Querying.
Robert Pienta, Acar Tamersoy, Alex Endert, Shamkant B. Navathe, Hanghang Tong, Duen Horng (Polo) Chau
International Working Conference on Advanced Visual Interfaces (AVI 2016).
Dissertations
Acar Tamersoy. CS. Co-adv: Sham Navathe. Spring, 2013 - Spring 2016. Proposed: Nov 6, 2015. Defended: Mar 11, 2016.
Thesis: Graph-based Algorithms and Models for Security, Healthcare, and Finance
Thesis: Graph-based Algorithms and Models for Security, Healthcare, and Finance
Received Symantec Research Labs (SRL) Graduate Fellowship, 2014-2015
Now: Researcher, Symantec Research Labs
Robert Pienta. CSE. Spring, 2013 - present. Proposed: Apr 6, 2016.
Thesis: Adaptive Network Exploration and Interactive Querying
Thesis: Adaptive Network Exploration and Interactive Querying
Code
MMap Code (BigData'14)
We have implemented several algorithms using memory mapping. Our preliminary executable jar can be downloaded here and will be available on GitHub soon.
In the current executable jar, we have included:
- Connected Components
- PageRank
- Triangle Counting
- One-Step Neighbors
- Two-Step Neighbors
- Please make sure Java 7 or higher is installed
- Download the Jar file using the button below and unzip it
- Carefully read README.txt contained in the folder
- Launch a command line window, change the directory that contains the Jar file
- Follow the instructions in README.txt to run algorithms
Below, we have included the links to download some large graph datasets and their binary versions (if allowed) on which the algorithms can run on.
The source code and executable jar are being distributed under MIT License
Download MMap Executable JarM-Flash Code (PKDD'16)
C++ code and documentation available at M-Flash GitHub repository.Large Graph Datasets
Below are some datasets we have used for evaluating our approach.
| #Node | #Edge | Source text file | Binary edge file | |
| LiveJournal | 4,847,571 | 68,993,773 | Link | Download |
| 41,652,230 | 1,468,365,182 | Link | Download | |
| YahooWeb | 1,413,511,391 | 6,636,600,779 | Link (requires Yahoo's NDA) | Unavailable due to NDA |
People
This project's researchers and contributors include:










Funding Agency and Acknowledgement
EAGER: Scaling up Machine Learning with Virtual Memory
NSF IIS 1551614
PIs: Polo Chau, Rich Vuduc
Funded: $184,904, 10/1/2015 – 9/30/2017
Program Manager: Aidong Zhang
NSF IIS 1551614
PIs: Polo Chau, Rich Vuduc
Funded: $184,904, 10/1/2015 – 9/30/2017
Program Manager: Aidong Zhang
This material is based upon work supported by the National Science Foundation under Grant No. IIS-1408287. Any opinions, findings, and conclusions or recommendations expressed in this material are those of the author(s) and do not necessarily reflect the views of the National Science Foundation.